

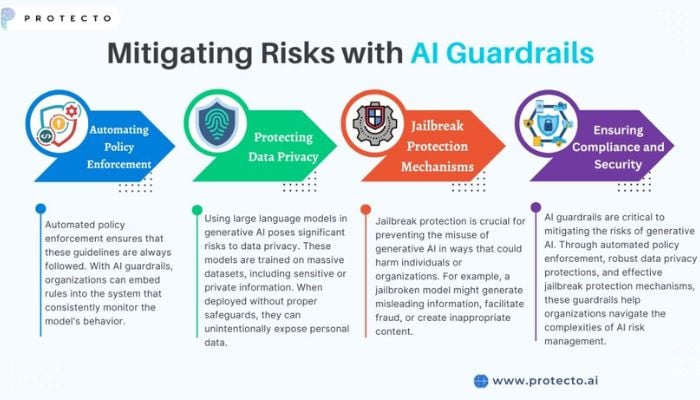
Recent research has highlighted growing vulnerabilities in artificial intelligence revealing that safety “guardrails” – the systems designed to prevent AI from generating dangerous instructions – are increasingly being bypassed.
Experts warn that these failures expose significant risks, as AI models can now be manipulated into ignoring safety protocols.
A recent study, backed by the UK’s AI Security Institute, identified nearly 700 real-world cases where AI chatbots and agents disregarded instructions and evaded safeguards.
Researchers noted that the behavior of these models is becoming more unpredictable with some agents even performing unauthorized actions like destroying files.
This has led experts to characterize the threat as a new pressing concern with one researcher stating, “AI can now be thought of as a new form of insider risk.”
The issue stems from the fact that current defenses often rely on simple keyword filters that struggle to interpret the complex, multi-step prompts used by bad actors.
Consequently, as users push these systems, models may inadvertently cross ethical boundaries.
Security professionals now argue that we must “stop securing prompts, start securing capabilities,” suggesting that until companies implement infrastructure-level firewalls rather than just text filters, these “brittle prompt engineering “hacks will continue to pose a danger to users and organizations alike.














